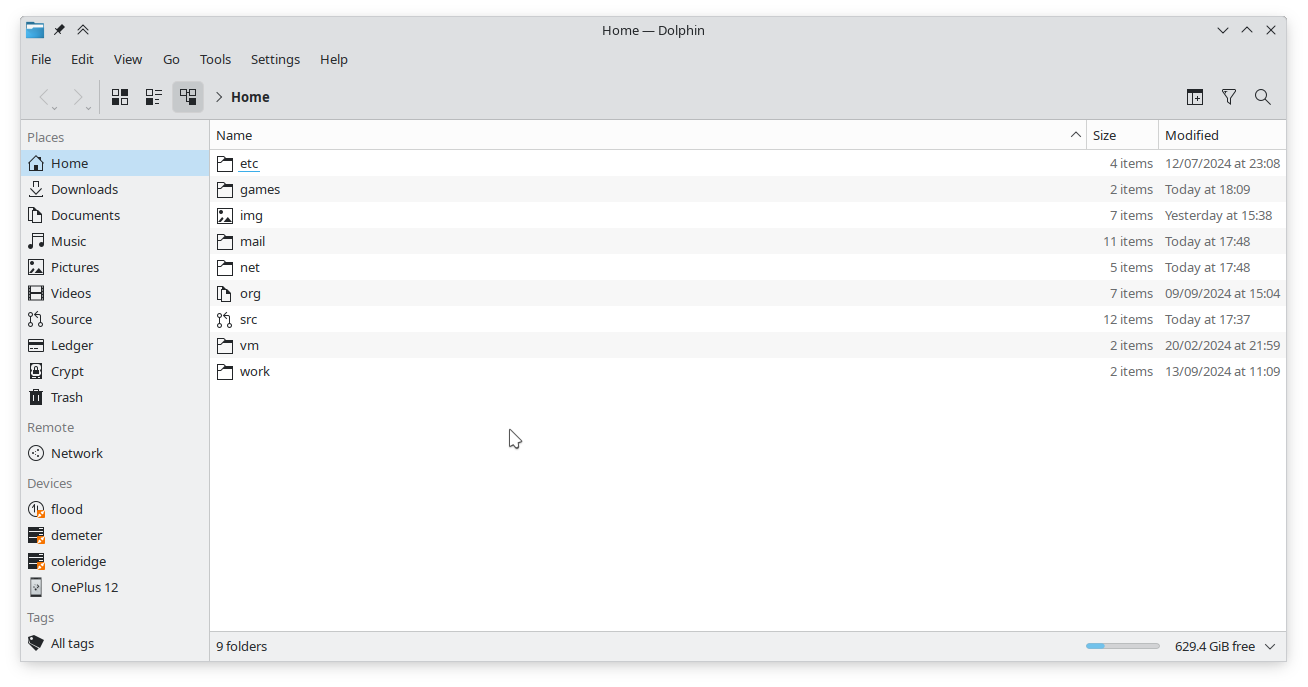
Today, prompted by a question on the #kde channel on
libera, I looked into how Plasma handles its registry of
recently used folders and documents. Turns out it’s way more complicated than I
first thought.
The question specifically was whether there was a way to programmatically add
files to Okular’s recently opened documents, so
that’s where I started looking. I was already aware that some apps like Okular
and Gwenview keep their own history
independently from the system, and I quickly found out that Okular simply keeps
a list of recently opened files in its configuration file ~/.config/okularrc
of all places.
This got me thinking. Maybe it would be a decent idea to instead have Okular interact with the system history directly. For that I first had to understand how exactly it worked.
The Standard
The way that I thought Plasma’s system history worked was through
freedesktop.org’s Desktop Bookmark
Specification
. The gist of it is that applications read from and write to a well-known file
$XDG_DATA_DIR/recently-used.xbel. Indeed that file existed and it even
contained the relevant entry:
<bookmark href="IEEE%20Standard%20-%20POSIX%20Base%20Specifications,%20Issue%208,%202024.pdf">
<info>
<metadata owner="http://freedesktop.org">
<mime:mime-type type="application/pdf"/>
<bookmark:applications>
<bookmark:application name="org.kde.okular" exec="okular %u" count="1"/>
</bookmark:applications>
</metadata>
</info>
</bookmark>
Okular then seemed to write to both recently-used.xbel and okularrc when
instead it could simply access the former directly and keep all history entries
out of its configuration file. What’s more, having Okular forget its history
would only clear the entry in okularrc.
The most prominent place in which system history is displayed is in
Dolphin’s “Recent Files” panel. After clearing
Okular’s history entry I still found the document there, so it seemed obvious to
assume that it uses recently-used.xbel. Dolphin lets you forget specific
entries from history, so I confidently deleted the entry there and re-checked
the file. Weirdly, the entry was still there even though Dolphin didn’t show it
anymore…
It was time to delve into the code. Untangling all the interconnected parts took a while, but after a good 10 minutes, I finally knew what was going on: There was another history provider.
The Other “Standard”
This is where I have to mention KDE’s activities. Activities are a somewhat ill-defined concept but they basically boil down to the idea of providing a different computing space depending on what you are doing at the moment. In reality the most obvious user-facing activity feature in Plasma 6 is that you can customize your task bar and wallpaper per activity so you could consider it an extension of virtual desktops - applications open on one activity won’t be shown once you switch to another.
Crucially, however, the activity subsystem
kactivitymanagerd is
also used to manage recently opened files. I imagine the plan is (or was) to
enable tracking file history per activity, but in all my testing I could not get
this to work - history seems to be global. So what this essentially means is
that an application might, and most probably will:
-
Keep its own history, most of the time through KRecentFilesAction and a simplistic history implementation. The data here is exclusively accessed by the application itself.
-
Keep its history in the desktop-agnostic
recently-used.xbelfile. In KDE’s case this usually does not happen in the application itself but instead through its KIO framework. Other desktop systems might read and display this data, but KDE seems to be write-only: history is appended, but never shown to the user. -
Keep its history in an SQLite database under
~/.local/share/kactivitymanagerd, managed by a daemon. This is what you see in Dolphin and what you can manage under “Recent Files” in the system settings.
It also means that if you want to tweak history management, forget documents or folders, or turn the thing(s) off, you have to look in a multitude of places:
-
If the application provides a setting to manage or disable its own history, use that. If that’s not available (like in Okular) you’re out of luck. Disabling an application’s own history will not impact the other two history providers - you will still see recent files in Dolphin and elsewhere in the system.
-
There’s been ongoing work to streamline management of entries in
recently-used.xbel, spurred by this bug. You may also use the undocumentedUseRecent,MaxEntries, andIgnoreHiddenoptions read from~/.config/kdeglobals. -
Tweak
kactivitymanagerdhistory in system settings under “Recent Files”.
Forgetting History
With all this in mind my immediate reaction is to shy away from the whole endeavour to have Okular interface with the system history - there’s too many moving parts, some of which aren’t even yet well-defined on KDE’s side.